
今回はunityのml-agents toolkit(v0.6.0)に含まれるサンプルシーン全14種をまとめていきます。
ml-agentsに含まれる学習モデルを応用するだけでもおもしろそうなことができるのではないかと思い、それぞれのサンプルの特徴をまとめてみたいと思った次第です。
ml-agentsについて知らない方でもわかるように簡単な説明も加えておくのでぜひ見てってください。
ML-Agentsサンプルシーン一覧
1. Basic
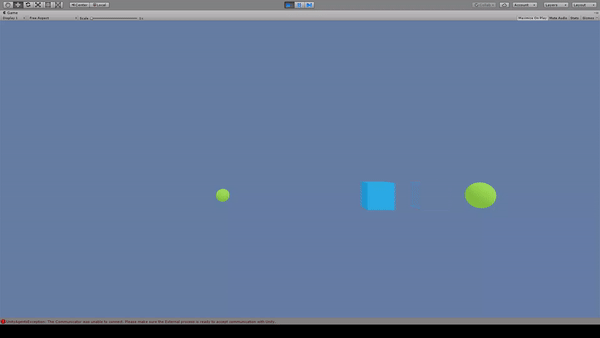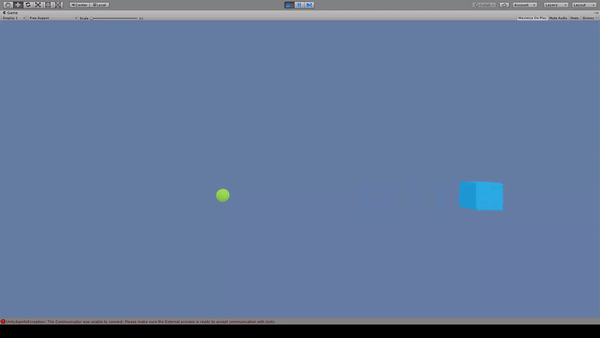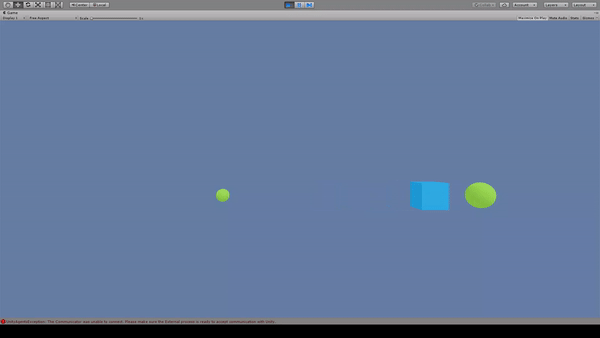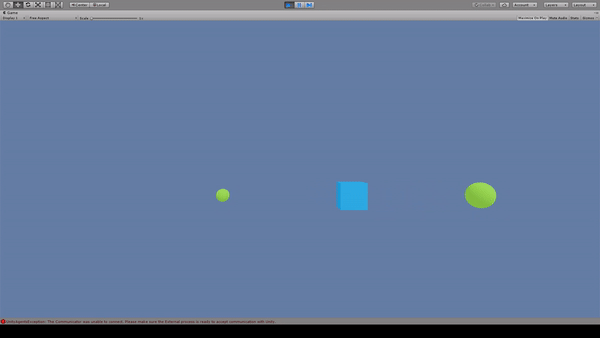
Agent:青いキューブ
Reward:
大きいスフィアに到達で+1.0
小さいスフィアに到達で+0.1
Penalty:なし
報酬が最大となるように大きいスフィアに移動している。
2. 3D Balance Ball

Agent:青い板
Reward:ボールが板上にあるとき+0.1
Penalty:ボールが板から落ちたとき-1.0
ボールを落とさないように板の回転が制御されている
3. GridWorld
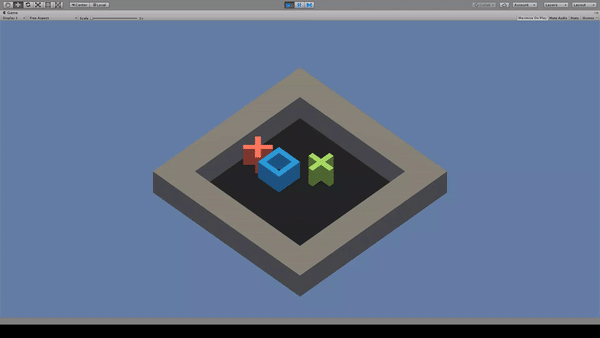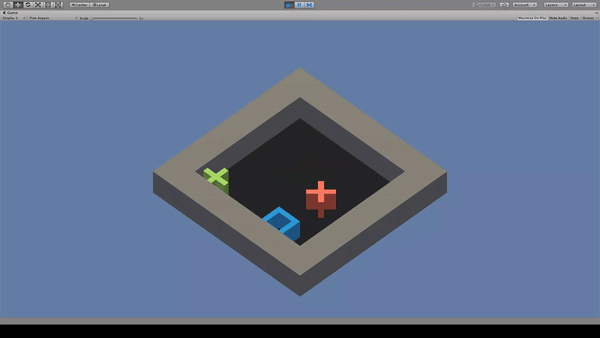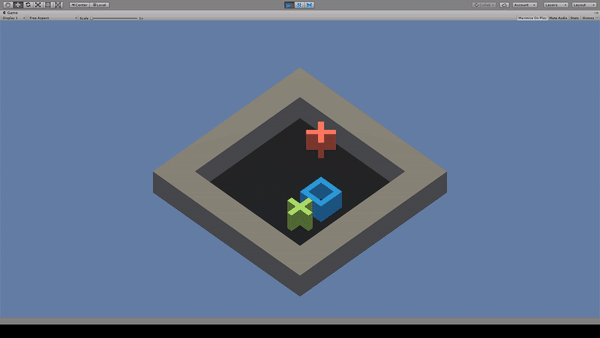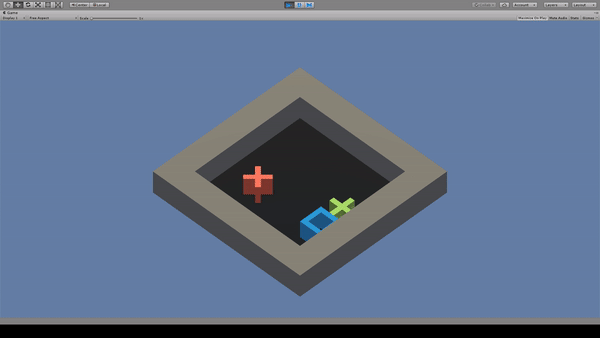
Agent:青い四角
Reward:緑色の×に到達で+1.0
Penalty:
毎時-0.01
赤色の×に到達で-1.0
赤色×を避けて緑色×に到達するように動く。しかし、たまに赤色×も踏んでいる。
4. Tennis
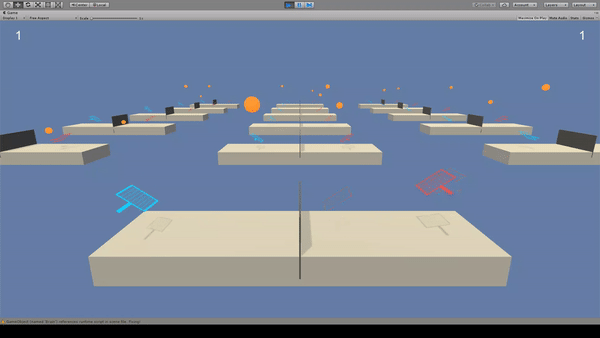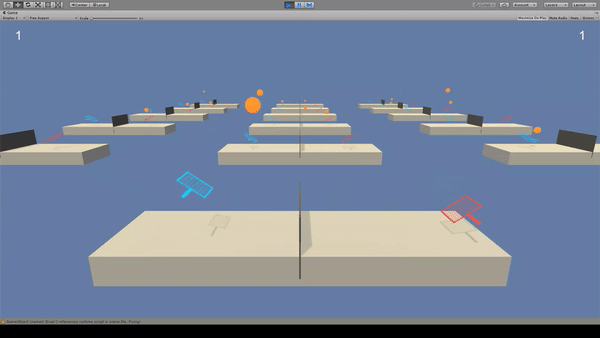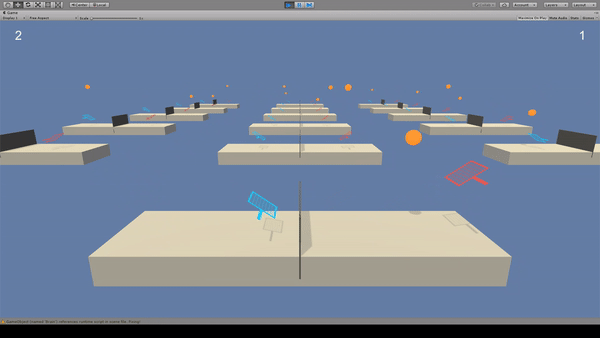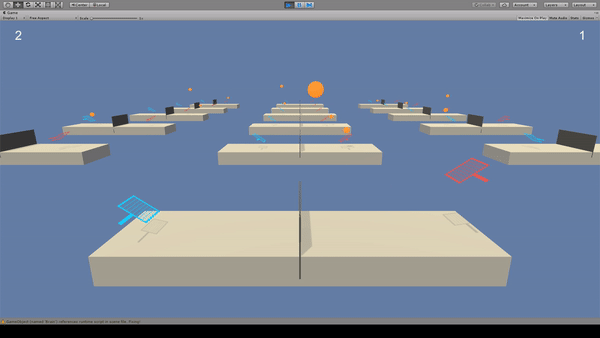
Agent:ラケット
Reward:ネットをボールが超えるように打つと+0.1
Penalty:ボールを地面につけたときとコートを超えたとき-0.1
青いラケットと同じBrainで赤いラケットも動いています。
5. Push Block

Agent:青いキューブ
Reward:黄色いブロックがゴールに到達で+1.0
Penalty:毎時-0.0025
黄色いブロックをゴールへ到達させるためにブロックの裏側から押していますね。毎時ペナルティが発生するので徐々に大きな力を加えてより早くゴールに着くようにブロックを動かしています。
6. Wall Jump
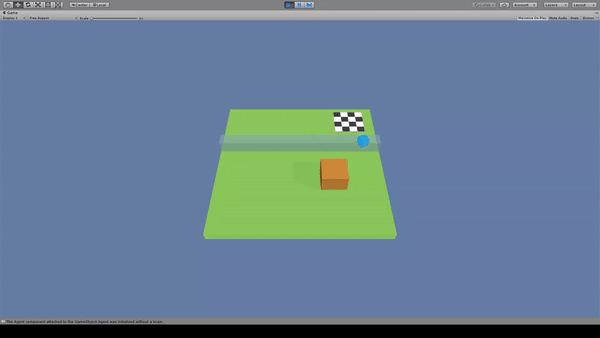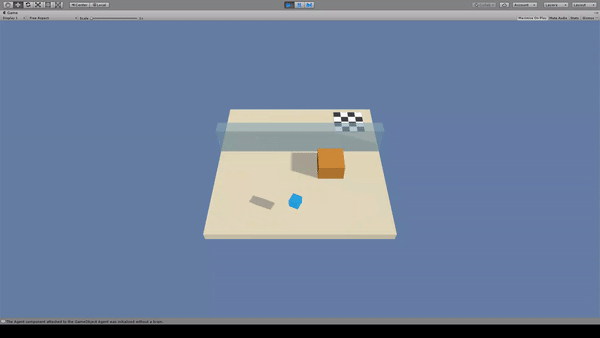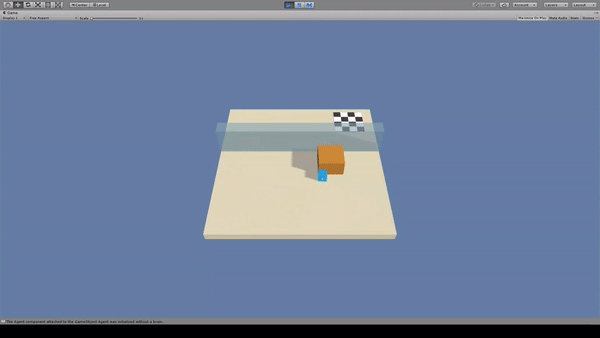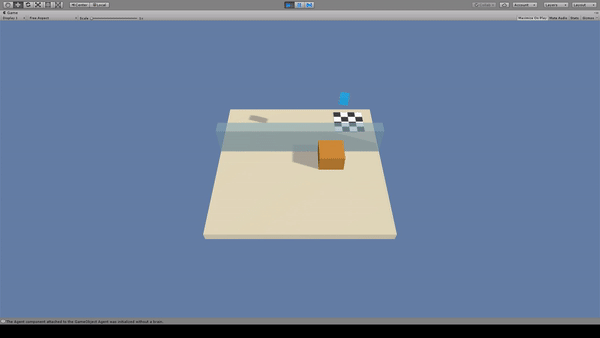
Agent:青いキューブ
Reward:ゴールに到達したとき+1.0
Penalty:
毎時-0.0005
プラットフォームから落ちたとき-1.0
Agentがジャンプしただけでは大きな壁は越えられないため、黄色いブロックを移動させて壁を乗り越えています。
7. Reacher
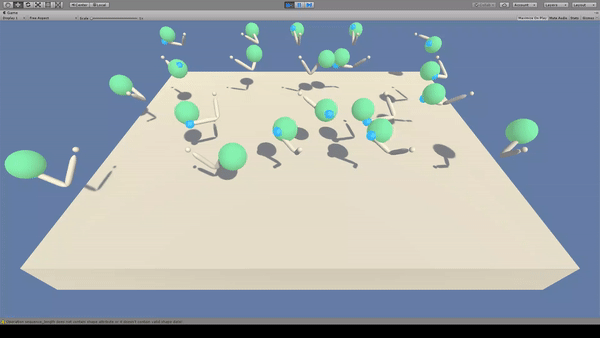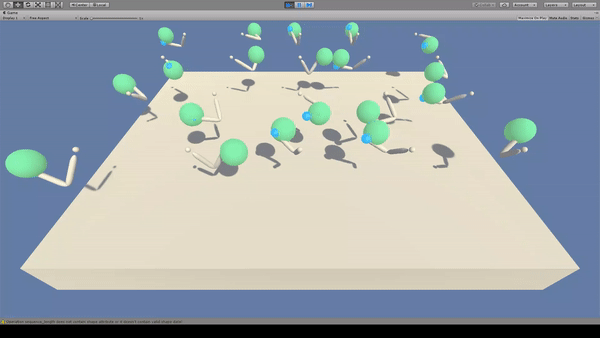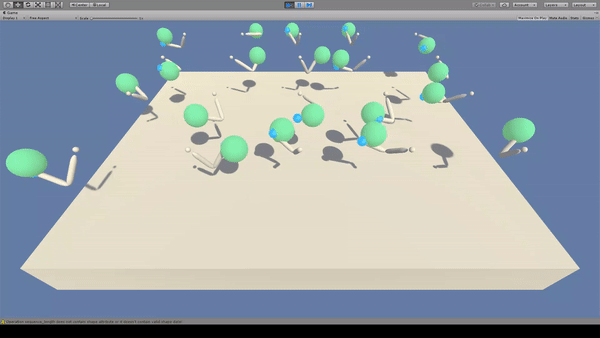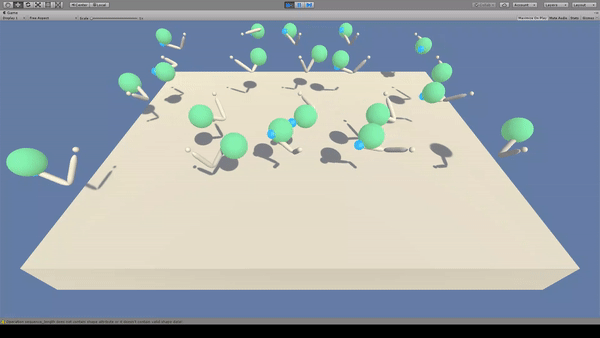
Agent:先端に青いスフィアのついた白色のアーム(2関節)
Reward:Agent先端の青色スフィアが緑色のスフィアに到達で+0.1
常に緑色のスフィアと青色のスフィアが接触する状態を保とうとします。
Penaltyがないため、移動はゆっくりかつ無駄がある印象です。
これだけは動画を見てもわかりずらかった。。。
8. Crawler

Agent:4足のくも?みたいなやつ
Reward:
ゴールの方向と体の向きが一致すると+0.03
体の移動方向上にゴールがあると+0.01
体の向き、進行方向をゴールの位置の関係を学習し、ゴールへ到達しています。
9. Banana Collector
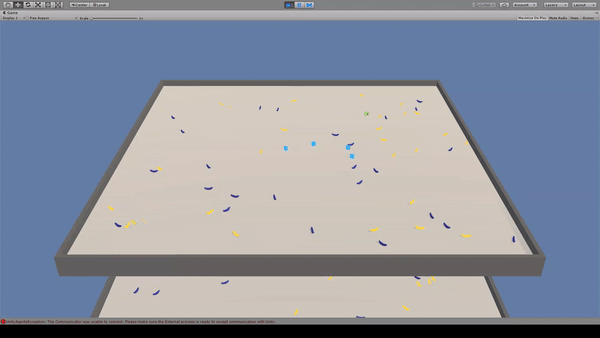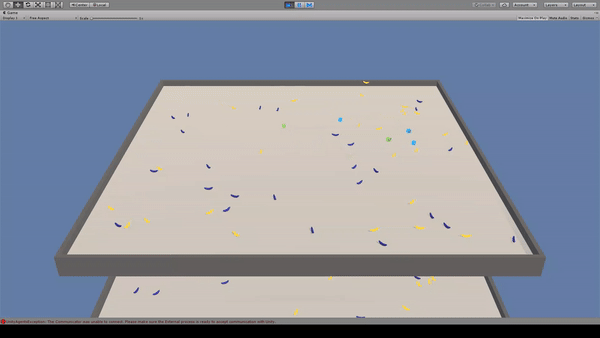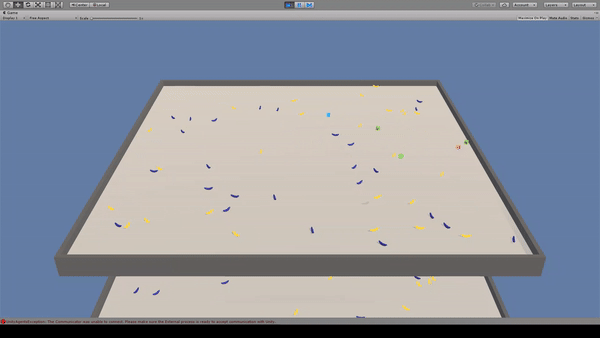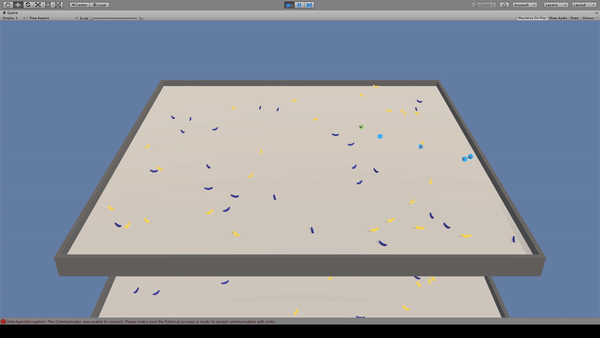
Agent:青いキューブ×4
Reward:黄色いバナナを取得で+1.0
Penalty:紫色のバナナを取得で-1.0
見えない光線を出してバナナの位置を確認し、バナナを取得しています。
10. Hallway
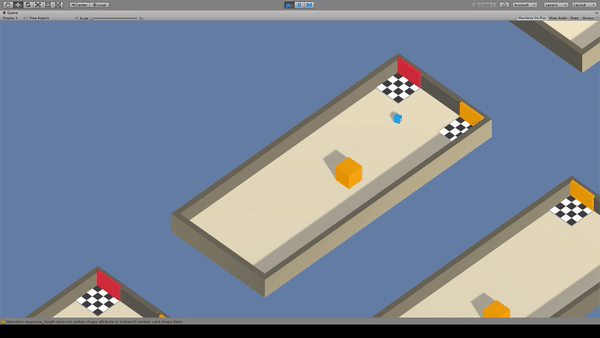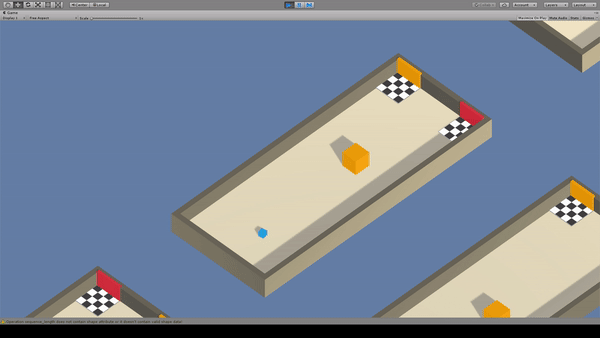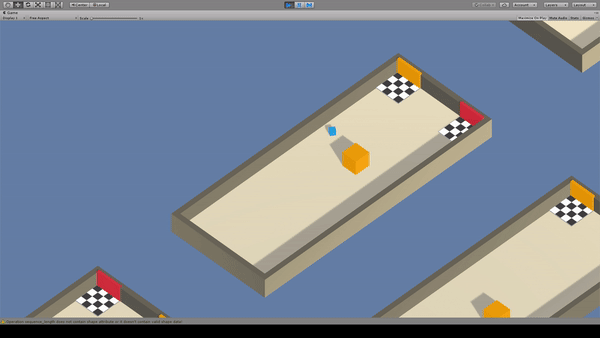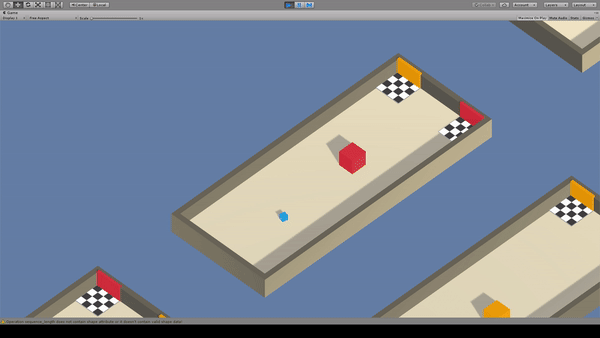
Agent:青いキューブ
Reward:障害物と同じ色のゴールへ到達で+1.0
Penalty:
毎時-0.0003
間違ったゴールに到達で-0.1
フィールド上の情報から、どちらのゴールが正解かを学習します。この例では障害物の色がゴールの正誤の判断基準となることを学習出来てますね。
11. Bouncer
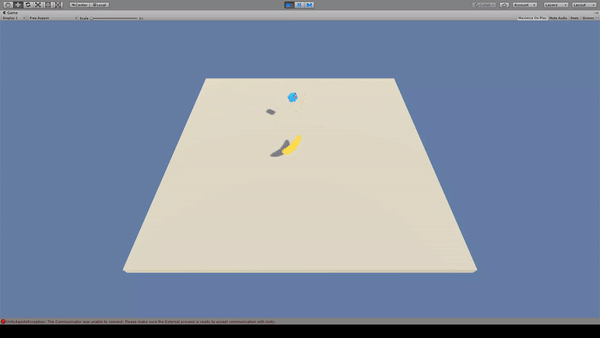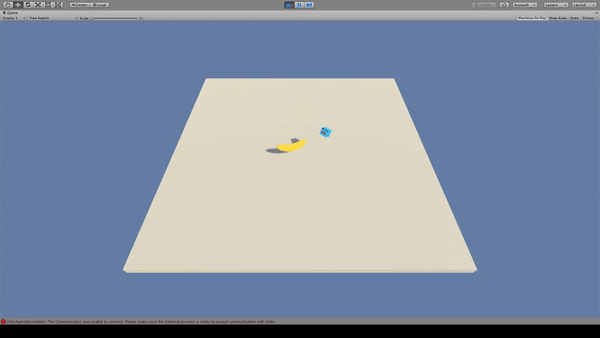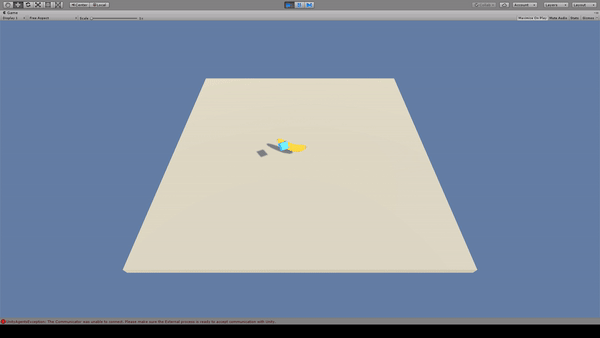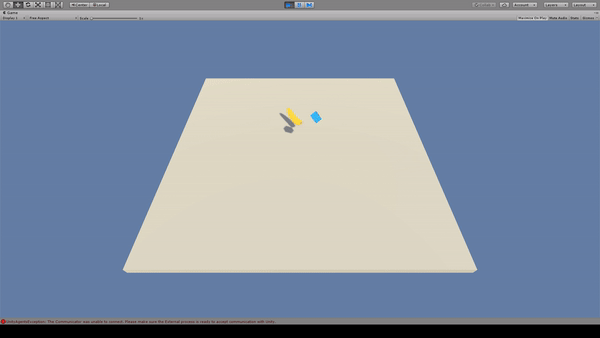
Agent:青いキューブ
Reward:バナナを取得で+1.0
Penalty:
一定回数以上ジャンプすると-1.0
毎時-0.05
Agentはバナナを取得するとRewardがもらえるため、バナナに向かってジャンプします。
12. Soccer Twos
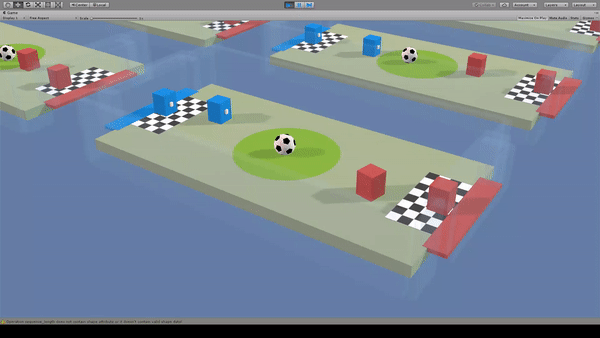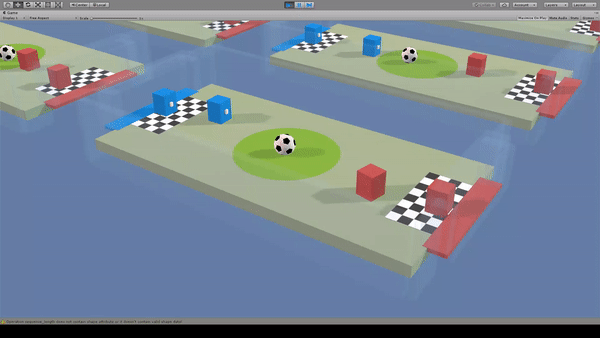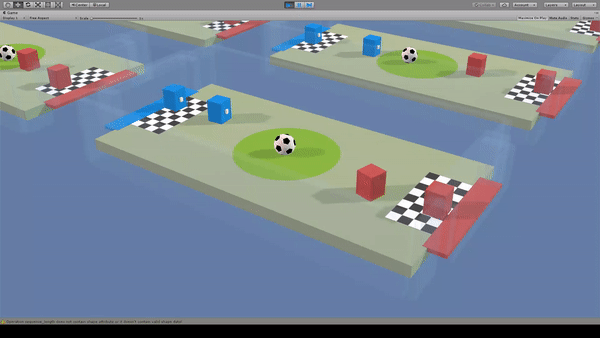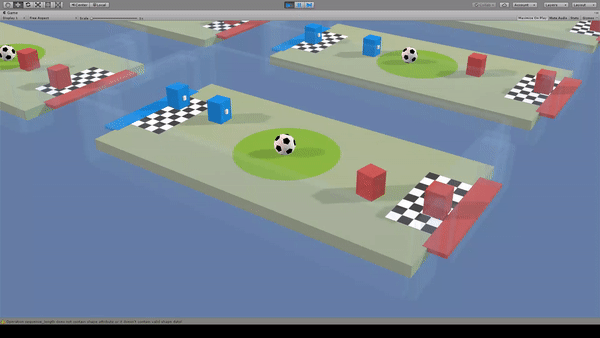
Agent:キューブ×4
ストライカー
Reward:ボールが相手のゴールに入ると+1.0
Penalty:ボールが自分のゴールに入ると-0.1
毎時-0.001
キーパー
Reward:ボールが相手のゴールに入ると+0.1
毎時+0.001
Penalty:ボールが自分のゴールに入ると-1.0
サッカーのミニゲールができます。ストライカーとキーパーは別々のBrainで学習しています。
13. Walker
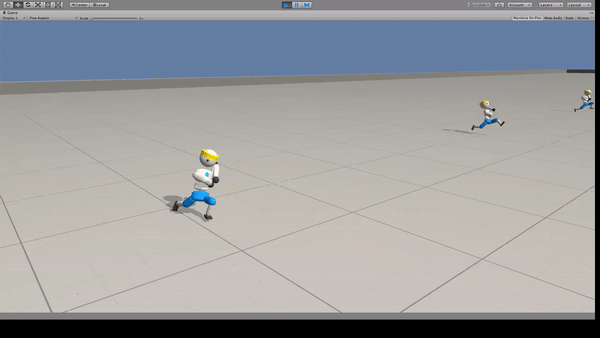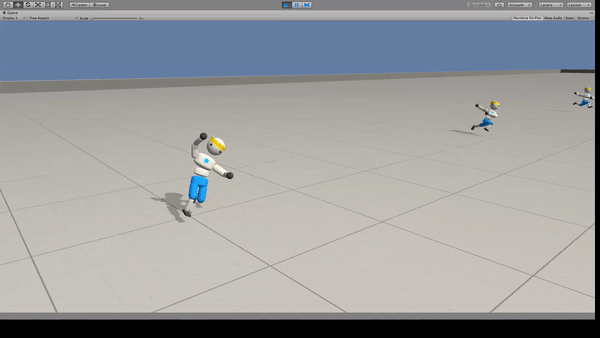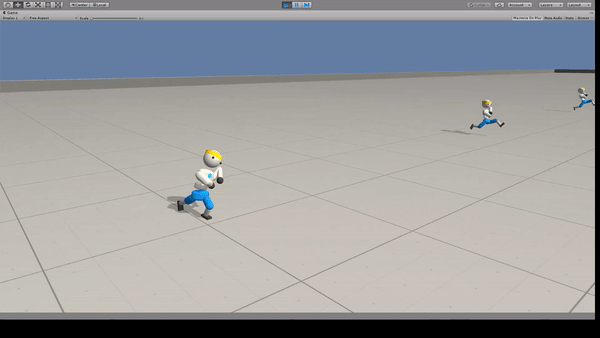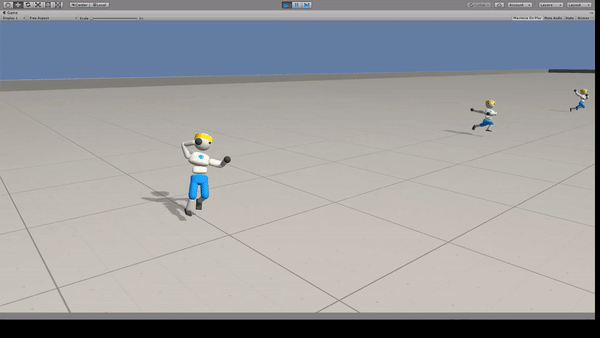
Agent:26自由度の人型モデル
Reward:
体の方向がゴールの向きにあると+0.03
頭のy座標を維持できたとき+0.01
体の向きとゴールの方向が一致したとき+0.01
Penalty:
体の進む方向と頭の進む方向がずれたとき-0.01
人型モデルに走ることを学習できます。
14. Pyramids
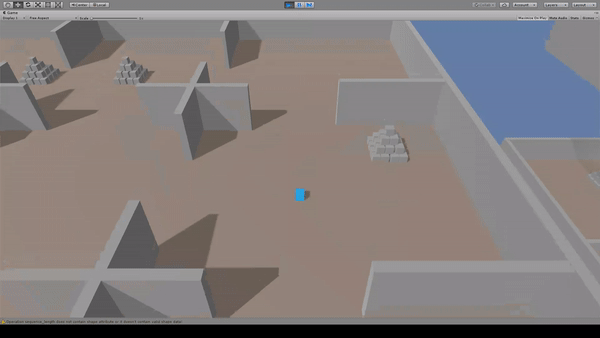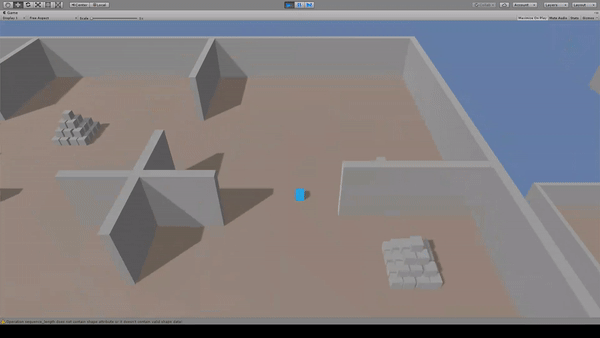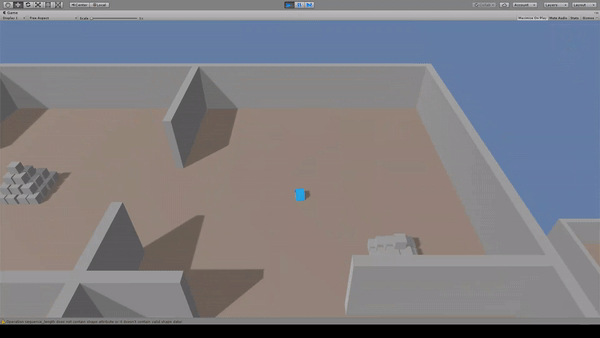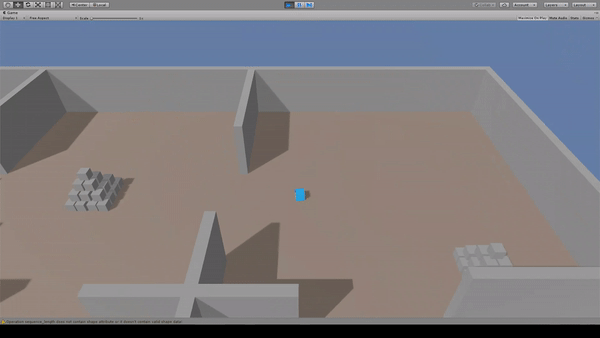
Agent:青いキューブ
Reward:ピラミッドに到達で+2.0
Penalty:動くたびに-0.001
ピラミッドへ向かって移動します。報酬を得た後は別のピラミッドへ向かって移動を続けます。
まとめ
今回紹介したシーンのさらに詳しい説明が知りたい方は、unity公式ml-agentsのガイドを参照してください。
基本的に内容が軽い順で紹介しました。一番最初のBasicのシーンで使われているAgentスクリプトは約130行でかけてしまうので、ml-agentsの中身を学ぶにはちょうどいいと思います。
ml-agentsに関する書籍もあるので、気になる方は参考にしてみてください。
最後まで読んでいただきありがとうございました。