今回は、Unityで機械学習ができるツール「ML-Agents」を使ってUnityちゃんを動かしてみました。
学習した機能はシンプルなもので、Unityちゃんを操作し、ターゲットのキューブに接触したら報酬がもらえるようになっています。
試行回数はいろいろやってみて全部で100万回です。そこで得た知見を共有出来たらなと思います。
結論から言いますと、少し残念な終わり方になってしまいました。端的に学習がうまくいかなかったってことです。
せっかく読みに来てくださった方の期待を裏切ってしまうかもしれませんが、この記事を読んで、ML-Agentsを使えばこんなことができることを知っていただければ幸いです。
■ML-AgentsでUnityちゃんを動かしてみた結果
まず結果を張っておきます。100万回学習した結果、こんな感じになりました。
・失敗の原因を考える
今回の学習が失敗した原因について、私なりに考えてみました。
前回試した、球体を動かす学習と照らし合わせて考えています。
前回の学習したシーンはこんな感じです。
<考えられる原因1つ目>移動方法を前後移動+左右回転にしたこと
まず1つ目は、Unityちゃんの操作を前後移動+左右回転の4パラメータにしたことです。
球体の場合は前後左右に移動させても、球体前後ろに違いはないので、気にしないで動かせました。
しかし、Unityちゃんの場合は、前後左右に違いはありますよね。
球体を動かすように左右に移動するとカニさん歩きのような結果になり、違和感がでてしまいます。
そのため前後に移動し、左右に回転できるように設定しました。
移動方法を変えたので、それにともなって取得するデータに回転座標も加えてみましたが、うまくいきませんでした。
<考えられる原因2つ目>報酬・学習データの設定ミス
2つ目の原因は、報酬、学習データの設定ミスです。
これらは学習の要になる重要な設定です。Agentが正しい行動をすることで報酬を与え、正しくない行動をした時にはペナルティを適切に与える必要があります。
俗に言うアメとムチ的なやつです。
学習データはその名の通り、機械学習して最適なパラメータを決める元となるデータのことです。
適した学習データを与えないと、何が正しくて、何が悪いのか機械が学習できません。
例えば、数学のテストで良い点を取るためには、数学の問題を解く必要ですよね。
それなのに、国語の練習問題を与えてしまって数学とは全く関係ないことを学習している状況に陥ってしまったわけです。
これら2点が合わさってよくわからんくなってしまいました。思い当たるものを試してみましたがなかなかうまくいかずじまいでした。
参考までに、今回どんな設定を試したのか簡単に載せておきます。
前提として、球体の学習時に与えた学習データはあらかじめ含まれていて、そこへ新たに学習データを追加していきました。
| 追加した学習データ | 結果 |
| 球体学習時のデータのみ(X,Z座標(ジャンプはしないため、2軸で十分)・X,Z速度・ターゲットとの相対座標) | 回転をする割合が多く、その場から全然動かない |
| Unityちゃんの前方を示すベクトル(X,Y,Zの3つ) | Unityちゃんが前後に動くようになる。動きすぎて地面から落下しまくる。 |
| Unityちゃんの回転座標(X,Y,Zの3つ) | ターゲットの近くに接近、立ち止まり、後ろ歩きで落下していく。←今回はここで終了 |
・100万回学習して学んだこと
100万回という膨大な回数学習すれば、少しは学ぶだろうと安直に考えていました。
100万回学習したときの学習結果をご覧ください。
学習回数は右肩上がりに精度が上がっているときのみ増やす価値があるもので、やみくもにやっても結果はでませんでした。
1万回ほど試行し、うまくいかない場合は見切りをつけてほかの設定をするべきでしたね。
まずは学習データの選定が重要です。数学のテストなら計算ドリル、英語のテストならラクタンですね。
■100万回学習した先に…
100万回で止めてしまったわけですが、もしも200万、300万と学習を積んでいったらちゃんと機械学習はできていたのでしょうか。
この疑問を解決すべく、自分なりに調べてみました。
・このまま学習させていいのか?
結論から言いますと、このまま学習させても良い結果は得られなかったです。
100万回の学習した結果は以下のような値がでました。
|
1 2 3 4 5 6 7 8 9 10 |
INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1150000. No episode was completed since last summary. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1151000. Mean Reward: -187.635. Std of Reward: 188.315. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1152000. Mean Reward: -1.957. Std of Reward: 1.544. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1153000. No episode was completed since last summary. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1154000. No episode was completed since last summary. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1155000. Mean Reward: -7.478. Std of Reward: 10.214. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1156000. Mean Reward: -1.590. Std of Reward: 1.990. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1157000. Mean Reward: -2.533. Std of Reward: 4.031. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1158000. Mean Reward: -3.700. Std of Reward: 1.071. Training. INFO:mlagents.trainers: uniuni-0: UnitychanLearningBrain: Step: 1159000. Mean Reward: -3.930. Std of Reward: 1.093. Training. |
No episode was completed since last summary. Training.はステップが終わらない場合に表示されます。
今回は動かないとこの結果になります。
Mean Rewardが報酬の平均値、Std of Rewardが報酬の標準偏差です。
つまりMean Rewardが大きくなるほどよい精度となります。
今回は100万回で1度もプラスの値にならなかったので、学習が進んでいないことになります。
以下の画像の緑色のような曲線になったと考えています。
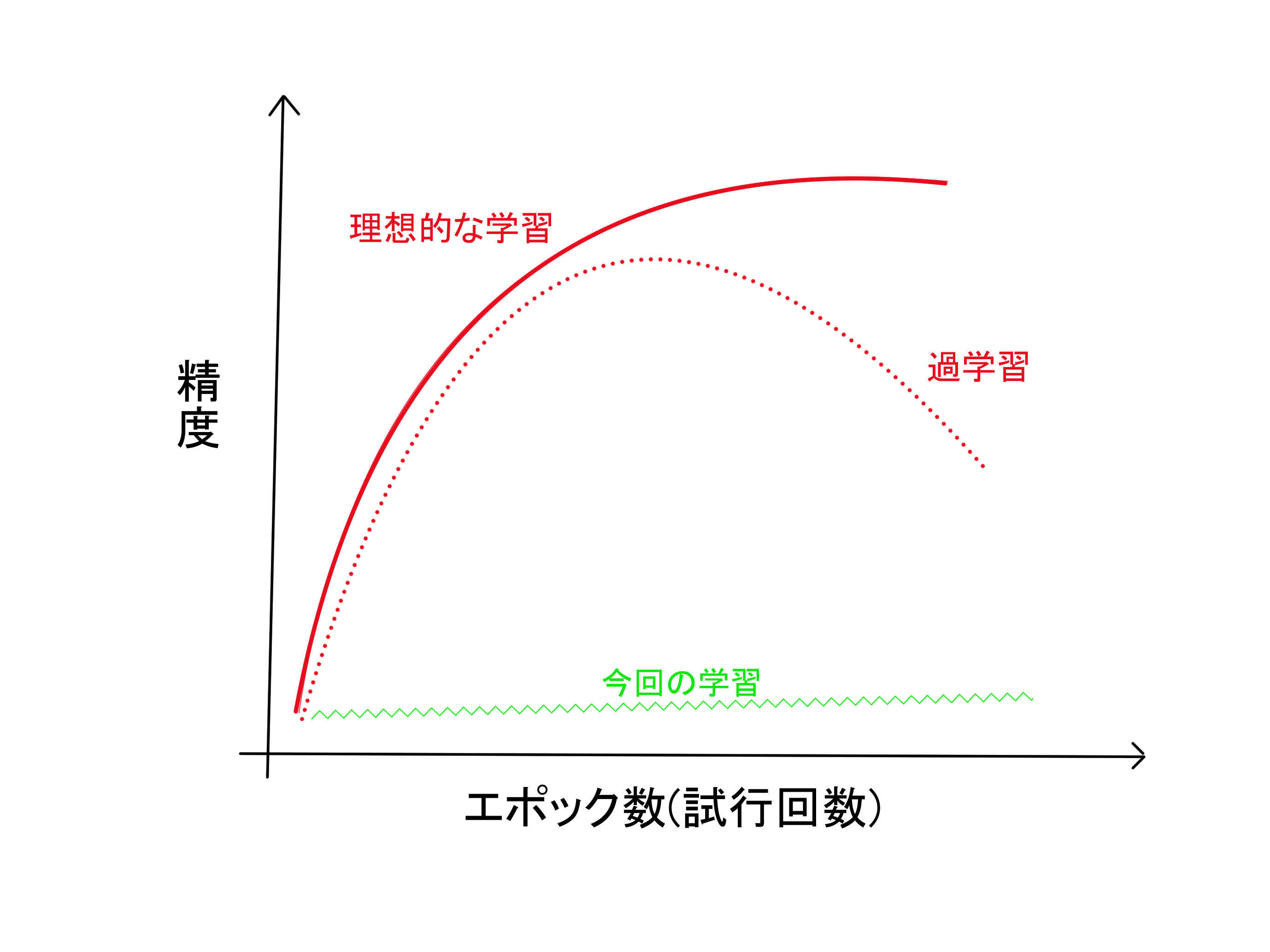
今回は過学習は考えなくてもよいですが、ちゃんとした学習が行えていると赤色の曲線のように右肩上がりで精度が向上していきます。
今回は報酬は増減を繰り返すだけで、上昇しませんでした。
なので、100万回以上学習しても効果はなさそうと感じて学習を終了しました。
・一般的な学習回数は?
私なりに調べてみた結果、最適なパラメータの設定ができていれば数万回ほど学習回数で、それなりの成果が得られるようです。
やはり、1万回ほど試行したのちに試行回数を増やすか、パラメータをいじるかを決めていく流れが正しそうですね。
ML-Agentsで機械学習をする際は、私の方からは以下のような手順で開発することをおすすめします!
・学習データ、報酬の設定をする
・1万回試行し、 No episode was completed since last summary. Training.が起こらない、かつMean Rewardが右肩に伸びているときだけ、試行回数を増やす
・1万回試行しても精度が上がらない場合は、パラメータの設定をし直す
■まとめ
簡単にできると思っていましたが、そうはいきませんでしたね。
今回失敗したunityちゃんは必ず動かしてみせるので、もうしばらく待っててください!
私から、これからml-agentsを使う皆様にお伝えしておきたいのは以下の3点です。
・学習データ、報酬の設定で学習できるかが決まる
・試しに1万回試行
・試行回数だけ増やしても効果はない
最後まで読んでいただきありがとうございました。

この作品はユニティちゃんライセンス条項の元に提供されています