Pythonを使って画像をスクレイピングしてみたい…
この記事を読めば、画像をスクレイピングする流れと、実際にやるときの注意点を知ることができます。
今回はPythonを使ってWeb上にある画像をスクレイピングしてみました。
この記事では、スクレイピングの流れと私がスクレイピングしてみてわかんなかったこと、その解決方法についてまとめていきます。
■Pythonを使って画像をスクレイピングする流れ
画像をスクレイピングする流れをまとめていきます。以下に書いていく手順ですが、1番目と2番目の手順は、自力でやらなくてはいけません。完全自動にはできないかもなので、その点は割り切ってやっちゃいましょう。
1ウェブページ内の画像の位置を見つける
まず初めにすることは、ウェブページ内の画像の位置を見つけることです。どうやるかといいますと、スクレイピングしたいWebページにアクセスして、ソースコードで位置を探します。
スクレイピングしたいWebページをブラウザで開いて、「F12」キー(もしくはCtrl+Shift+Alt)を押してみてください。
以下の画像のような表示に切り替わるかと思います。
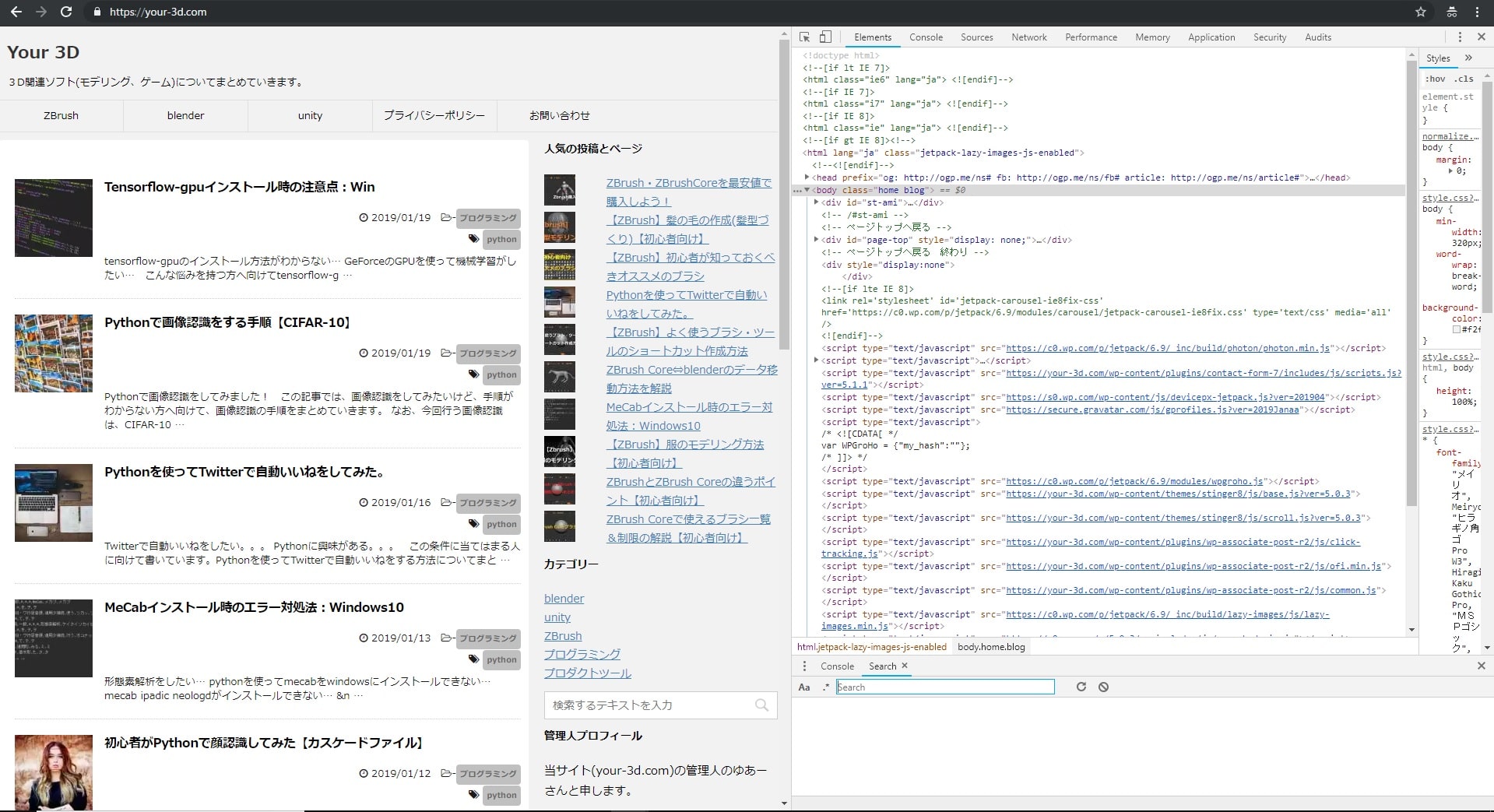
この右側に見えるのがソースコードで、表示されているwebページがどのようにコーディングされているかを確認することができます。
ウェブページに表示されている画像などを右クリックして、「検証」をクリックすると、クリックした表示物に対応するソースコードが表示されます。
今回は私のブログのトップページにある画像すべてをスクレイピングしてみたいので、画像を右クリック、「検証」してみると、「src=https://i」というコードが共通して使われていますね。
このコードが画像の位置を示していることがわかりました。
2画像を保存するフォルダをつくる
画像の場所がわかったら、次に画像を保存するフォルダをつくっておきましょう。
ここでの注意点としては、ファイル名だけです。
これは経験談なのですが、Pythonを使ってファイル名に「-(ハイフン)」が含まれるファイルを読み込もうとしてエラーが発生しました。
学習してても名前や変数に-(ハイフン)を使わずに_(アンダーバー)を使っている人が多いです。
もしもにそなえて「-(ハイフン)」は使わないようにおすすめしておきます。
画像フォルダはどこにおいても大丈夫です。わかりやすいところがおすすめ。
ここまでで、スクレイピングの前準備は完了です。いよいよスクレイピングしていきましょう!
3Pythonでコーディングして画像をスクレイピング
いよいよコーディングしていくわけですが、私は以下の記事を参考に行いました。

以下が全コードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import requests from bs4 import BeautifulSoup import re import uuid url= "<span style="color: #ff0000;">https://your-3d.com</span>" #スクレイピングしたいwebページのurl req = requests.get(url) soup = BeautifulSoup(req.text, "lxml") imgs = soup.find_all("img", src=re.compile('^https://i')) #<span style="color: #ff0000;">https://i</span>の部分を適宜変更する for img in imgs: print(img["src"]) req= requests.get(img["src"]) with open(str("<span style="color: #ff0000;">画像保存用フォルダへのパス/img/</span>")+str(uuid.uuid4())+str(".jpeg"),"wb") as file: file.write(req.content) |
コード上の赤文字の部分を適宜変更することで、希望のwebページをスクレイピングすることができます。
注意点としては、imgs = soup.find_all(“img”, src=re.compile(‘^https://i’))の部分で、「^」が付くことです。書き換えたりするときに消したら絶対に気づかないので要注意です。
ソースコードで、src=https://~~~とあると思うので、この、https://~~~の部分を適宜書き換えるようにできれば大丈夫です。これは、https://~~~から始まるパスに画像があるということを示しています。
また、with open(str(“画像保存用フォルダへのパス/img/“)+str(uuid.uuid4())+str(“.jpeg”),”wb”) as file:の”画像保存用フォルダへのパス/img/“の部分は、手順2で作成した画像保存用フォルダへのパスを入れてください。
パスは対象フォルダを開いて、以下の画像を参照すればわかります。*クリックで拡大できます。

実行結果は以下のようになります。
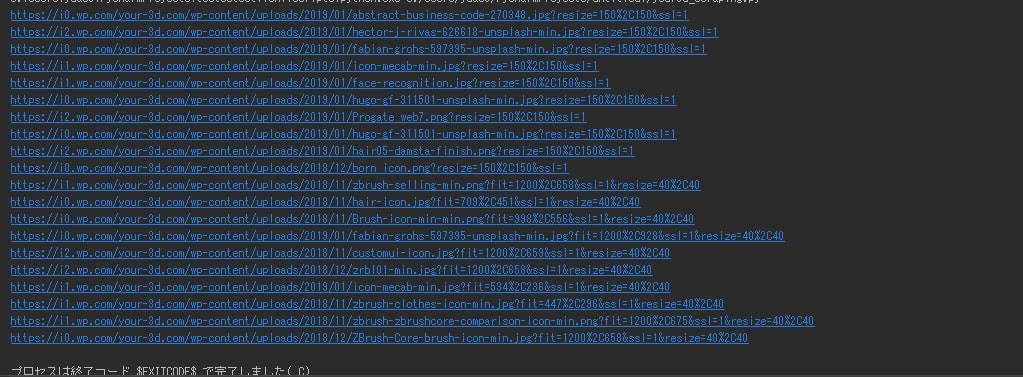
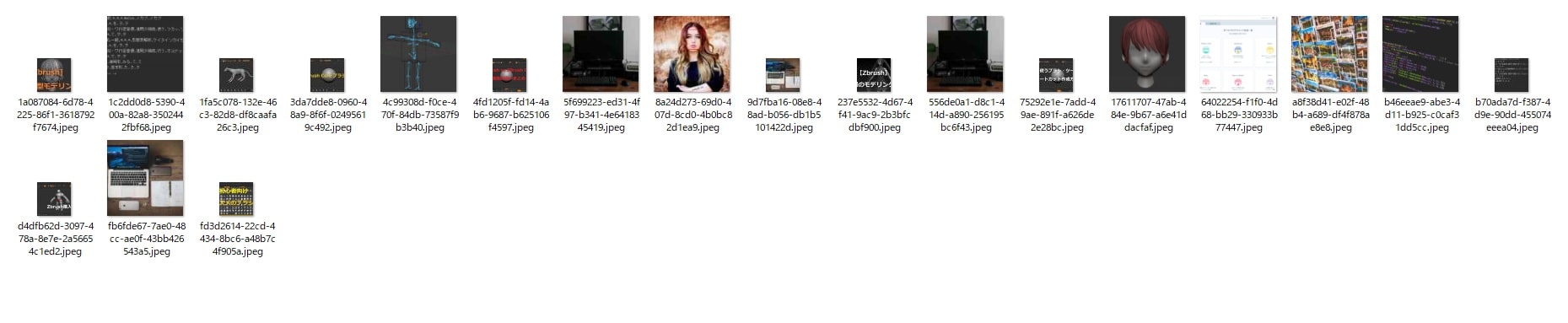
ここまでで、指定webページの画像スクレイピングについてはおしまいです。お疲れ様でした。
■まとめ
この記事で、画像のスクレイピングの流れがだいたいわかっていただければ幸いです。
この記事と、紹介させていただいた記事を合わせれば、画像のスクレイピングはできるようになるわけですが、注意してほしいことがあります。
それは、web上ではスクレイピングを禁止しているサイトだったり、サーバーに負荷を与えてしまい点です。
故意でなくとも、相手の迷惑になりえますので、十分に注意してスクレイピングをしましょうね!
最後に感想~。
今回画像のスクレイピングをしたわけですけど、そもそもやってみた理由ていうのが、画像認識のためのデータセット作成のためなんですよね。この記事では、画像収集のポイントだけ押さえました。次回の記事で、取得した画像にラベル付けをする方法についてまとめたいと思います。
画像認識系のことばっかりやっているけど、自分がやりたいのはモデリングをAIですることなんで、実現はまだまだ先ですね。。。
最後まで読んでいただきありがとうございました。
※追記※
GANsで機械学習をするためのデータセット作成方法を、以下の記事にまとめました。
機械学習用の画像データセットをつくりたい方はぜひよんでみてください。
ぶっちゃけるとこの記事の10倍は読みやすいかと思います。