機械学習を自分の手でやってみたいけど、データセットのつくり方がわからないという疑問を解決します。
本記事では機械学習用のデータセットのつくり方についてまとめておきます。
対象は、Tensorflow、keras等のチュートリアルコードを動かしてみた方です。
機械学習についてまったく知らないという方はまずはチュートリアルコードを動かしてみるのがおすすめです。

本題に入る前に少し余談です。TensorflowやMNISTのチュートリアルは、データセットのダウンロードから読み込みまで全部コード内でやってくれます。
そのため、コード中で何が起きてるのかいまいち理解できなくてモヤモヤした経験がありました。なので私はデータセットに対して疑問が残ってしまったので、データセットを1からつくってみたいと思った次第です。
さて、ここから本題に入ります。
本記事で作成した機械学習用データセットは、以下のようなものです。
- ラベルなし
- リサイズ処理
- 顔画像(カスケードファイルにより処理)
- 不要データを自分で取り除く必要あり
ラベル付けをしていないということで、本記事で作成したデータセットは分類問題を学習するためにそのまま投げ入れることはできないので注意して下さい。
GANs(敵対生成ネットワーク)により顔画像を生成するために作成したので、今回は画像なら顔部分を切り出し、リサイズしたデータセットになります。
顔認識はカスケードファイルを用いて行いましたが、顔ではない部分を切り出していることが多々ありますので、そこは手作業で削除等の処理が必要です。(↓の画像のimg780.jpgとか)
最終的に作成できたデータセットはこんな感じです。
![]()
↑のようなデータセットをつくるためには、以下の手順が必要です。
- Webから画像をスクレイピング
- 顔部分の切り出し
- 取得画像を整形(リサイズ、不適な画像を処理)
個人的に一番しんどいのはなんといってもスクレイピングする部分です。自作しようとしたけど無理でした。
なので、以下で紹介するスクレイピング用コードはShunta KomatsuさんのQiita記事で紹介されているコードを丸々使っています。
画像を大量に取得できればあとは画像を処理するだけです。手順2、3については、1つのスクリプトとしてまとめて処理していきます。
それでは手順に沿ってデータセットのつくり方を解説します。
<開発環境>
・Python3.6.5
・glob 0.6
・opencv-python 4.0.0.21
・urllib3 1.24.1
1.Webから画像をスクレイピング
Webから画像をスクレイピングして、データセットのもととなる大量の画像をスクレイピングします。
使用したスクリプトはShunta KomatsuさんのQiita記事(API を叩かずに Google から画像収集をする)から、丸々お借りしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 |
import argparse import json import os import urllib.request import urllib.error import urllib.parse from bs4 import BeautifulSoup import requests class Google(object): def __init__(self): self.GOOGLE_SEARCH_URL = "https://www.google.co.jp/search" self.session = requests.session() self.session.headers.update( { "User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:10.0) \ Gecko/20100101 Firefox/10.0" } ) def search(self, keyword, maximum): print(f"Begining searching {keyword}") query = self.query_gen(keyword) return self.image_search(query, maximum) def query_gen(self, keyword): # search query generator page = 0 while True: params = urllib.parse.urlencode( {"q": keyword, "tbm": "isch", "ijn": str(page)} ) yield self.GOOGLE_SEARCH_URL + "?" + params page += 1 def image_search(self, query_gen, maximum): results = [] total = 0 while True: # search html = self.session.get(next(query_gen)).text soup = BeautifulSoup(html, "lxml") elements = soup.select(".rg_meta.notranslate") jsons = [json.loads(e.get_text()) for e in elements] image_url_list = [js["ou"] for js in jsons] # add search results if not len(image_url_list): print("-> No more images") break elif len(image_url_list) > maximum - total: results += image_url_list[: maximum - total] break else: results += image_url_list total += len(image_url_list) print("-> Found", str(len(results)), "images") return results def main(): parser = argparse.ArgumentParser(argument_default=argparse.SUPPRESS) parser.add_argument("-t", "--target", help="target name", type=str, required=True) parser.add_argument( "-n", "--number", help="number of images", type=int, required=True ) parser.add_argument( "-d", "--directory", help="download location", type=str, default="./data" ) parser.add_argument( "-f", '--forc', help="download overwrite existing file", type=bool, default=False, ) args = parser.parse_args() data_dir = args.directory target_name = args.target os.makedirs(data_dir, exist_ok=True) os.makedirs(os.path.join(data_dir, target_name), exist_ok=args.forc) google = Google() # search images results = google.search(target_name, maximum=args.number) # download download_errors = [] for i, url in enumerate(results): print("-> Downloading image", str(i + 1).zfill(4), end=" ") try: urllib.request.urlretrieve( url, os.path.join(*[data_dir, target_name, str(i + 1).zfill(4) + ".jpg"]), ) print("successful") except BaseException: print("failed") download_errors.append(i + 1) continue print("-" * 50) print("Complete downloaded") print("├─ Successful downloaded", len(results) - len(download_errors), "images") print("└─ Failed to download", len(download_errors), "images", *download_errors) if __name__ == "__main__": main() |
ただし、Python3系では、urllibはurllib.request, urllib.error, urllib.parseの3つが別々のものになったため、3つにわけて宣言する必要があるので注意して下さい。
スクレイピングする際は、コンソール上で以下のコードで実行できます。
|
1 2 |
$ python 実行ファイル名 -t 検索キーワード -n 取得する数 $ python imgscraping.py -t face -n 100 |
なお、検索する画像の数は私の場合だと1000枚までしか取得できませんでした。調べてないので確定できませんが、おそらくリクエスト制限にひっかかっているためだと思います。
そのため、1000枚以上の画像を取得するにはスクリプトを変更するか、地道に集めるしかないようです。
しかし、試しにデータセットをつくるためなら十分な数を集められます。
収集したデータは、以下のパスにフォルダとして保存されます。
スクリプトのあるディレクトリ\data\検索キーワード名フォルダ/
私の場合は、”woman+face”、”woman+model+face”の2つのキーワードで1000ずつスクレイピングし、エラーを除いて約700枚のデータを収集しました。
2.顔部分の切り出し+3.取得画像を整形(リサイズ、不適な画像を処理)
画像を取得できればあとは画像処理するだけです。
顔部分をカスケードファイルを用いて認識、切り出し、全画像のサイズを統一します。
カスケードファイルとはOpenCVの公開している顔の特徴をまとめたデータになります。画像とカスケードファイルを照らし合わせて、顔がどの部分にあるかを調べます。
以下のリンク先からカスケードファイルをダウンロードしましょう。
カスケードファイルはたくさんありますが、今回は以下のファイル名のものをダウンロードしてください。保存先は画像処理用のスクリプト(.py)と同じディレクトリにしてください。
|
1 |
haarcascade_frontalface_alt.xml |
顔認識、画像整形用のコードは以下になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import cv2 import glob HAAR_FILE = "haarcascade_frontalface_alt.xml" cascade = cv2.CascadeClassifier(HAAR_FILE) load_img_list = [] face_cut = [] count= 0 #出力画像のディレクトリパス output_path = "./data/output/" #加工元の画像ディレクトリパス img_list = glob.glob("./data/face/*.jpg") for img in img_list: load_img_list.append(cv2.imread(img)) for load_img in load_img_list: face_rects = cascade.detectMultiScale(load_img) print(face_rects) if(len(face_rects) !=0): for face_rect in face_rects: x = face_rect[0] y = face_rect[1] w = face_rect[2] h = face_rect[3] face_cut = load_img[y:y + h, x:x + w] face_cut = cv2.resize(face_cut, dsize =(256, 256)) img_name = output_path + "img_" + str(count) + ".jpg" cv2.imwrite(img_name, face_cut) count += 1 else:pass |
このスクリプトでは2つのディレクトリパスを指定しているので、ご自身の環境に合わせて変更してください。
スクリプトについて説明をしておきます。
|
1 2 |
import cv2 import glob |
opencv-pythonとglobの宣言です。
globは画像をまとめて取得する際に使用します。
|
1 2 |
HAAR_FILE = "haarcascade_frontalface_alt.xml" cascade = cv2.CascadeClassifier(HAAR_FILE) |
カスケードファイルを読み込みます。” ”内にカスケードファイルのパスを指定するだけでOK。
|
1 2 3 4 5 6 7 |
load_img_list = [] face_cut = [] count= 0 #出力画像のディレクトリパス output_path = "./data/output/" #加工元の画像ディレクトリパス img_list = glob.glob("./data/face/*.jpg") |
load_img_list:画像ファイルのリスト
face_cut:顔認識して切り出した画像ファイルを格納する変数
output_path:出力画像の保存先 ファイル名(output)のフォルダを作成しといてください。スクリプトのあるディレクトリ/data/outputの順になるように配置します。
img_list:加工元の画像ディレクトリを指定します。globにより.jpgのファイル全てのファイル名を取得します。
|
1 2 |
for img in img_list: load_img_list.append(cv2.imread(img)) |
img, img_list: 画像ファイル名の配列です。
load_img_listに画像を読み込みます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
for load_img in load_img_list: #顔の部分を識別 face_rects = cascade.detectMultiScale(load_img) print(face_rects) #顔が1つ以上検出されたら実行 if(len(face_rects) !=0): for face_rect in face_rects: x = face_rect[0] y = face_rect[1] w = face_rect[2] h = face_rect[3] #顔を切り出し face_cut = load_img[y:y + h, x:x + w] #画像リサイズ face_cut = cv2.resize(face_cut, dsize =(256, 256)) #ファイル名を決定 img_name = output_path + "img_" + str(count) + ".jpg" #画像書き込み cv2.imwrite(img_name, face_cut) count += 1 else:pass |
わかりにくいのでコメントで全部書きました。
注意していただきたいのが、カスケードファイルを用いた顔認識では、1枚の画像から複数の顔を検出できます。
このスクリプトでは、複数の顔が検出された場合、それら全ての顔を書き出すようになっています。
face_rectsに画像1枚から検出されるすべての顔座標が格納されています。
実際に動かしてみると、加工前はこんな感じ。

加工後は以下のようになります。
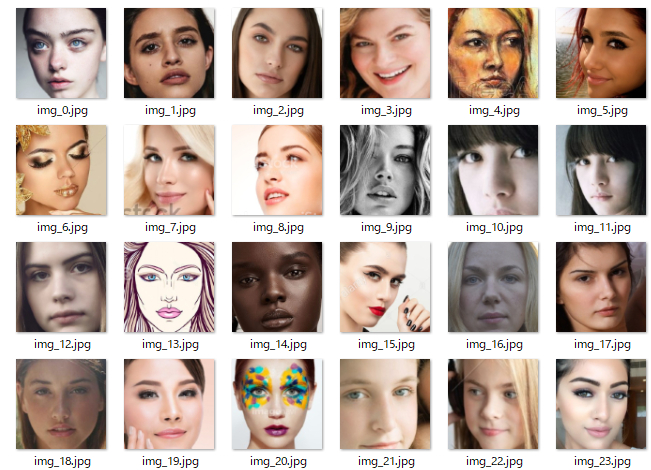
加工前後で画像が異なるのは取得する画像の順番が0→1→2の順でないためです。globでは0→1→10→100の順に読み込んでいます。
まあ画像の順番は変わりますがあまり気にしなくても大丈夫でしょう。全部処理されているので安心してください。
あとは処理した画像の中から、不要なデータを取り除くだけです。
上の一覧にはおかしなものは見当たりませんが、データセットの中にはちょくちょく誤認された画像が含まれています。横向いているのもできれば避けた方がいいかもしれません。
ここの作業も自動化したかったのですが、方法がわからず私は手作業で行いました。数千枚なら間違い探しも一時間もかからないと思うのでここはわりきって手作業するのがはやいです。

これで顔画像データセットの完成です。画像の番号を順番に整列したい方は以下のスクリプトを実行してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import glob import cv2 import os path = "./data/output/" #加工元の画像ディレクトリ out_path ="./data/output_row/" #ファイル名を整形済み画像の保存先 if not os.path.isdir(out_path): os.makedirs(out_path) count = 0 img_name_list = glob.glob(path + "*.jpg") for img_name in img_name_list: name = out_path + "img_" + str(count) + ".jpg" img = cv2.imread(img_name) cv2.imwrite(name, img) count += 1 |
data/output_rowにファイル名が整列して保存されます。
今回は以上となります。
この手順によって30分程度で数千枚程度のデータセットをつくれるかと思います。
お試しでニューラルネットワークに学習させるには十分な量だと思うのでぜひ試してみてください!
最後まで読んでいただきありがとうございました。